
随笔分类
分布式作业调度
作业,其实究根到底就是任务,作业调度,对应的便是任务的执行
在项目开发时,我们可能会存在这类需求:需要定时去做些任务、需要在特定的时间点去干特定的事情
Java中有去提供两个定时任务类供我们去实现此需求:Timer、ScheduledExecutorService,前者不想过于述说,只需要知道其是在单个线程中去执行的定时任务,可想而知,当定时任务量很多时,任务会出现串行执行的场景,这也是使用 Timer存在的坑;其次便是 ScheduledExecttorService的出现友好的去解决了 Timer存在的问题,定时任务转变为异步线程执行处理;
但无论是 Timer,还是ScheduledExecutorService,都无法去实现在特定的某个时间点去执行特定的某一个任务,它们支持的便是按照某频率去执行写任务,因此通常需要结合 Calendar去使用;其次,这些定时执行的任务对应的线程通常是在一个进程中,但我们的系统为了多可用,通常会部署在多个机器上,对应的便是对个进程,那么此时问题便来了,对于定时要去执行的任务,我们需要确保任务执行的幂等性,避免出现相同任务在指定时间点被重复消费多次;
so,当项目中存在过多定时任务时,为了管理方便以及任务消费的幂等性,我们需要再进行一层封装,但,我们的初衷是什么,为了实现个定时任务,需要在项目中考虑这些逻辑么,这些逻辑的梳理真的是有必要的么,如果我们又要去开新的一个项目,又要重来么?
so,分布式作业调度踊跃而出,我们也称之为调度任务中间件
实际上,SpringBoot 2.0就已经去整合了 Quartz框架,并且去提供了非常强大的定时任务功能
Quartz是一个功能比较强大的任务调度框架,可以满足更多复杂的调度需求,Quartz设计的核心类:Scheduler、Job、Trigger,其中,Job便是我们定义的需要调度执行的任务,Trigger负责设设置任务调度策略,Scheduler便是将二者组装起来,并触发任务执行;Quartz支持简单的按照时间间隔任务执行,还支持按日历调度方式,通过设置 CronTrigger表达式 (包括:秒、分、时、天、月、年)进行任务调度
除此之外,也存在着一些优秀、开源的调度任务中间件,如 Elastic-job、XXL-JOB
分布式任务调度注重实现的目标:
-
并行的任务调度
并行执行的任务需要多线程协调进行,如果此类型任务比较多的话,多线程本身便是瓶颈所在,因为单台机器的 cpu处理能力是有限的
但如果将任务调度程度分布式集群部署,便能够将并行执行的任务分派到集群中其它节点进程中去执行,即将任务进行分片处理,由不同的实例执行,以来提高任务调度的处理效率
-
高可用
如果一个实例宕机,并不影响其它实例执行任务
-
弹性扩容
以水平扩展的方式便能够并行执行任务的处理效率
-
任务的管理与检测
对系统中存在的所有定时任务进行统一的管理与检测,让开发人员与运维人员及时了解任务的运行状况,以便出现异常时即时的应急处理
-
任务执行的幂等性
主要由两种方式:
- 分布式锁
多个实例在执行任务时需要先获取到锁,如果获取失败则说明已经有其它实例在执行对应的定时任务了,那也就是没有必要再去重复执行了
- Zookeeper选举
Leader选举机制,实例执行任务时需要判断自己是否是 Leader,即只有 Leader才会去执行定时任务相关业务逻辑代码,这也能够实现任务执行的幂等性
Elastic-Job Lite
对 Quartz二次封装的开源项目,功能丰富强大,采用 ZK作为分布式协调,实现任务高可用以及分片治理
ElasticJob由两个相互独立的子项目 ElastciJob-Lite、ElasticJob-Cloud组成,提供了强大的弹性调度、资源管理以及作业调度的功能
ElasticJob Lite是轻量级的无中心化的解决方案,使用 jar包的形式提供分布式任务的协调服务,此组件负责任务的调度,并且产生日志以及任务调度记录
- 无中心化:指的是没有调度中心,传统的分布式任务调度器都是通过调度中心来对任务进行调度的,而去中心化是一种新的解决方案,每一个运行在集群中的作业服务器都是对等的,各个作业节点都是自治的、对等的、节点之间会通过注册中心来进行分布式协调
架构图:
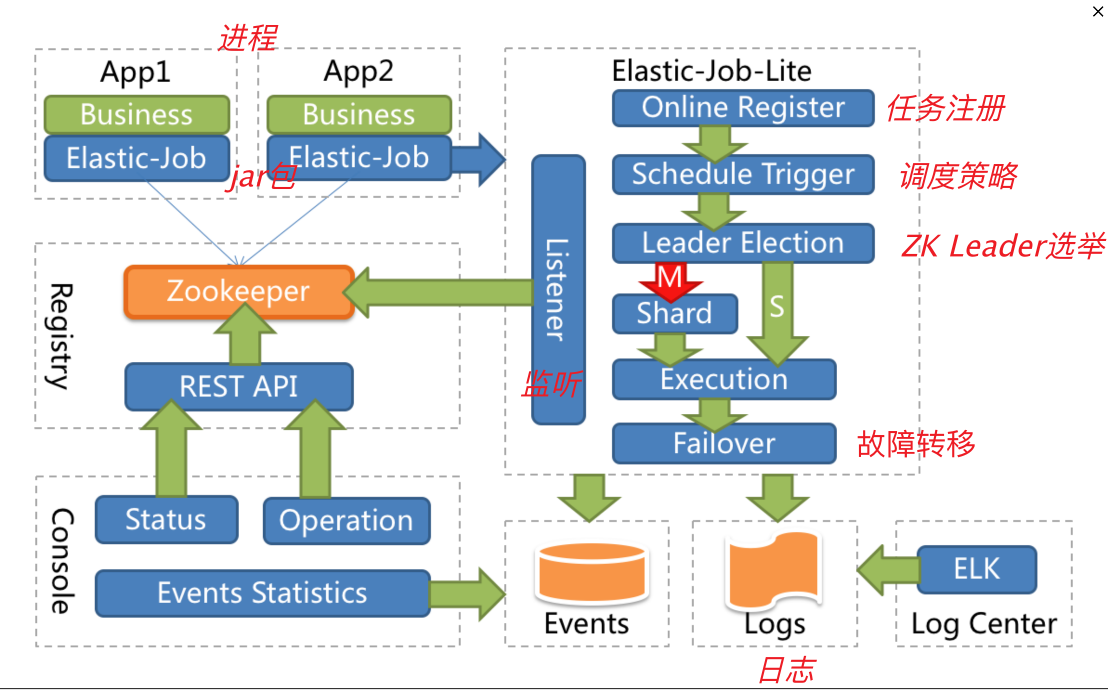
APP:每一个应用程序都会以 jar包形式引入 ElasticJob-Lite,其内部包含了具体任务执行逻辑以及 ElasticJob-Lite组件
Registry:以 ZK作为 Elastic-Job的注册中心组件,器里面存储了执行任务的相关信息,并且 Elastic-Job通过此组件进行 Leader选举以来解决任务执行幂等性,这也是其无中心化的具体解决方案;应用程序在启动时,其内嵌的 ElasticJob-Lite组件会向 ZK注册该实例信息,并且触发选举,从众多实例中选举出一个 Leader,让其执行任务,即当任务执行时机到时,ElasticJob-Lite组件会去驱动选举为 Leader的应用程序去执行具体的任务逻辑代码,并且会产生任务执行记录;并且当某个实例宕机时,ZK感知到后会重新进行 Leader的选举,这也便实现了分布式调度下的高可用性 (总结:ZK主要干两件事:作业信息的存储以及 Leader的选举)
-
Elastic-Job采用 ZK来去进行任务执行实例选举,先来了解下 ZK的 ZNode节点,ZK有四种类型的 ZNode,客户端在创建 ZNode时可以进行指定:
- PERSISTENT 持久化目录节点
客户端与 ZK建立连接时可以创建持久类型的 ZNode,当客户端断开连接时此节点依旧存在,其不允许创建重复的 key,如 /data,否则会创建失败
- PERSISTENT SEQUENTIAL 持久化顺序编号目录节点
区别于持久化目录节点的是,允许去创建相同的 key,但 zk会给节点名称进行顺序编号以来避免节点名称的相同
- EPHEMERAL 临时目录节点
客户端与 ZK断开连接时此节点会被删除,不允许创建相同的 key
- EPHEMERAL SEQUENTIAL 临时顺序编号目录节点
区别于临时目录节点的是,允许去创建相同的 key,但 zk会给节点名称进行顺序编号以来避免节点名称的相同
-
实例选举过程分析:
每一个 Elastic-Job任务执行实例会作为 ZK的客户端来去操作 ZK的 ZNode节点
- 任意一个实例启动时首先创建一个 /server的 PERSISTENT节点
- 多个实例同时创建 /server/leader PERSISTENT节点
- /server/leader的子节点只能创建一个,后创建的会失败,创建成功的实例将被选举为 Leader,用来执行任务
- 所有的任务实例节点会去监听 /server/leader的变化,一旦节点被删除了(如实例宕机),将会重新触发 Leader的选举,此时会去抢占式地创建 /server/leader节点,创建成功的便是 Leader
极简入门
定义 Job,实现 SimpleJob接口:
/**
* @Author: 夜痕
* @Date: 2021-12-12 1:37 上午
* @Description: elastic-job 任务需要实现接口:SimpleJob
*/
@Component
public class CustomizedJob implements SimpleJob {
private AtomicLong atomicLong = new AtomicLong();
private AtomicLong atomicLong2 = new AtomicLong();
private AtomicLong atomicLong3 = new AtomicLong();
/**
* 于此可实现任务分片
* @param shardingContext
*/
@SneakyThrows
@Override
public void execute(ShardingContext shardingContext) {
// 获取分片栏目
int shardingItem = shardingContext.getShardingItem();
switch (shardingItem) {
case 0:
TimeUnit.SECONDS.sleep(1L);
System.out.println("task 1 run " + atomicLong.incrementAndGet());
break;
case 1:
TimeUnit.SECONDS.sleep(2L);
System.out.println("task 2 run " + atomicLong2.incrementAndGet());
break;
case 2:
TimeUnit.SECONDS.sleep(3L);
System.out.println("task 3 run " + atomicLong3.incrementAndGet());
break;
}
}
}配置 ZK Registry:
@Configuration
public class ZKRegistryConfig {
/**
* ZK服务端地址
*/
private static final String ZK_REGISTRY_ADDRESS = "localhost:2181";
/**
* ZK命名空间
*/
private static final String JOB_NAMESPACE = "elastic-job-example";
@Bean(initMethod = "init")
public CoordinatorRegistryCenter coordinatorRegistryCenter() {
// ZK相关配置
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZK_REGISTRY_ADDRESS,
JOB_NAMESPACE);
// 减少 ZK超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
// 创建 ZK注册中心
ZookeeperRegistryCenter zookeeperRegistryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
return zookeeperRegistryCenter;
}
}Job配置,初始化作业:
@Configuration
public class ElasticJobConfig {
@Autowired
private CoordinatorRegistryCenter registryCenter;
@Autowired
private CustomizedJob customizedJob;
/**
* 初始化作业
* @return
*/
@Bean(initMethod = "init")
public SpringJobScheduler springJobScheduler() {
return new SpringJobScheduler(customizedJob, registryCenter,
createJobConfiguration(CustomizedJob.class, "0/2 * * * * ?", 3, null));
}
private LiteJobConfiguration createJobConfiguration(final Class<? extends SimpleJob> jobClass,
final String cron, final int shardingTotalCount, final String shardingItemParameters) {
Builder builder = JobCoreConfiguration.newBuilder("elastic-job-example-springBoot", cron,
shardingTotalCount);
if (StringUtils.isNotBlank(shardingItemParameters)) {
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration jobCoreConfiguration = builder.build();
// SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration,
jobClass.getName());
return LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(Boolean.TRUE).build();
}
}启动三个进程,运行效果:
进程一:
task 1 run 1
task 1 run 2
task 1 run 3
task 1 run 4
...
进程二:
task 2 run 1
task 2 run 2
task 2 run 3
task 2 run 4
...
进程三
task 3 run 1
task 3 run 2
task 3 run 3
task 3 run 4作业分片
作业分片指的是任务的分布式执行,需要将一个任务拆分成多个独立的任务项,然后由分布式的应用实例来去执行其中的一片或多片
通过合理的任务分片,可以达到任务并行处理的效果,最大限度的提高任务执行的吞吐量
Elastic-Job并不直接提供数据处理的功能,只管将任务进行分片 (分片逻辑由程序员自己定义),然后将分片任务派分到不同应用实例上执行,因此开发者需要处理好分片项与真实数据的对应关系
通常为了最大化利用资源,我们会去将分片项设置为大于应用实例的数目,这样的话作业能够充分利用好分布式应用实力资源,以来动态实现资源调配,这样也是有好处的,比如当应用实例宕机时,为了不丢失分片项,会去重新进行分片项的路由,此时相对而言也能够提升分布式下应用实例的整体吞吐量













